

今、「AIエンジニアになりたい!」って方が増えています。
そんな憧れの職種(?)ですが、現在私は現役AIエンジニアとしてAI関連のシステム開発(具体的にはレコメンド技術を使ったWebサービス開発)に携わっております。(まあ、こんな感じで仕事しています。(^-^))

私の紹介はここまでにして、、、
今回は『リモートワークで注目のオンライン会議システムの議事録を自動で作成できないか?』にチャレンジしてみたいと思います。
具体的には、(次のような感じで)ZOOM会議システムで録音した録音データをGoogleの提供するSpeech-to-Text APIでテキスト変換して議事録を作成する、といったステップで考えています。
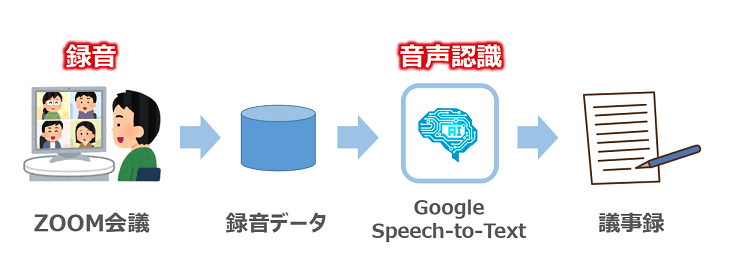
【図:オンライン会議の議事録を作成するまでのステップ】

もっと体系的にPython+AIを学びたい!って方におすすめのプログラミングスクールを紹介しております。
-

【徹底取材】PythonでAI・機械学習が学べるプログラミングスクールおすすめ6選を比較!
つづきを見る

【STEP1】GoogleのCloud Speech APIを使えるようにする

Google Cloud Platformの利用登録
Cloud Speech-to-Text APIを使うには、まず初めにGoogle Cloud Platform(以下、GCP)の利用登録が必要になります。
GCPの無料お試しは?
GCPでは、クレジットカードを登録することで、12か月間、300ドル分無料でサービスを利用することが可能です。無料枠を使い切っても、課金が勝手に開始されない点も安心となっております。
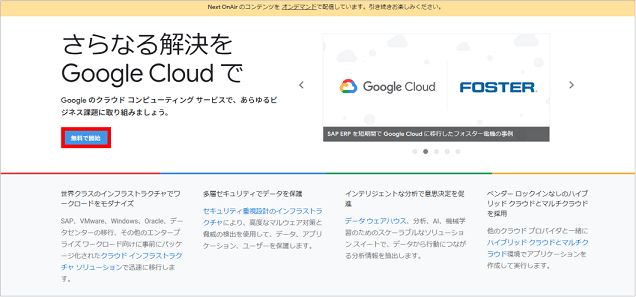
まずは、GCPトップページの「無料で開始」ボタンをクリックし、Googleアカウントでログインします。
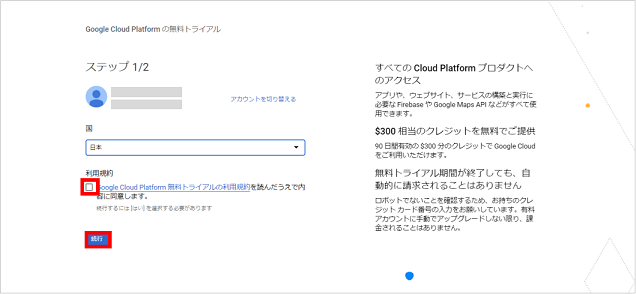
GCPの無料トライアル登録画面が表示されますので、住んでいる国(日本)を選択後、利用規約に同意し「続行」ボタンをクリックします。
そして次の画面で、「住所」「名前」「電話番号」「クレジットカード番号」を入力し、「無料トライアルを開始」ボタンをクリックします。(この後、Google Cloud Console画面が表示されます。)

プロジェクトの作成
それでは次に新しくプロジェクトを作成していきます。
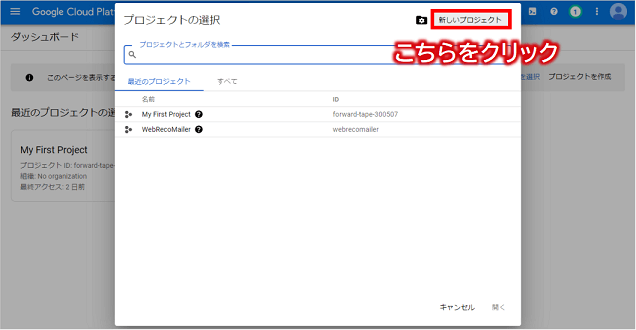
Google Cloud Console画面上部にある「プロジェクトを選択」をクリックし、ポップアップ画面右上の「新しいプロジェクト」ボタンをクリックします。
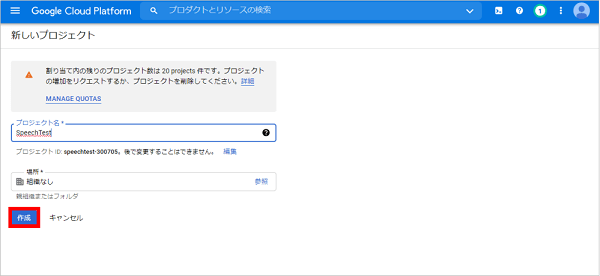
そして次の画面にて、プロジェクトの名前(今回は、SpeechTestとしました)をプロジェクト名欄に入力し、「作成」ボタンをクリックします。(この後、SpeechTestのプロジェクト画面が表示されます。)
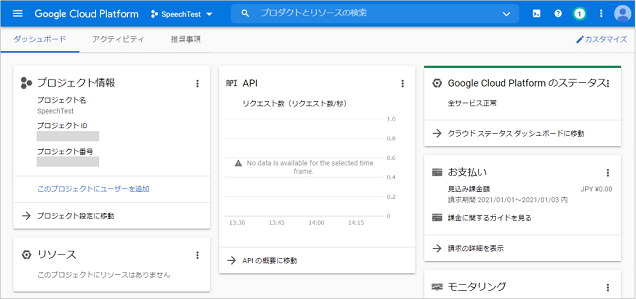
Cloud Speech APIの有効化
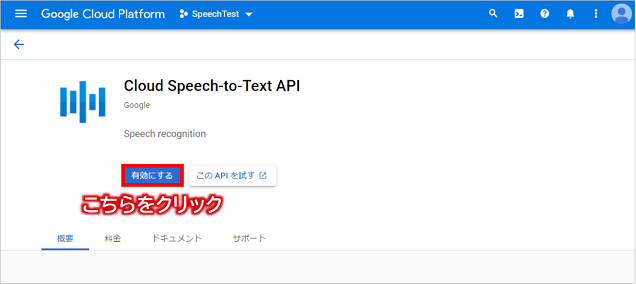
次に、プロジェクト画面上部の検索ボックスに「Cloud Speech-to-Text」と入力し検索を実行し、
次のCloud Speech-to-Text API画面にて、「有効にする」ボタンをクリックしてAPIを有効化します。
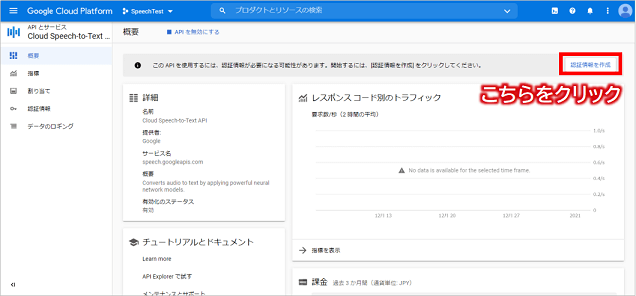
サービスアカウントキーの取得
次にサービスアカウントキーを取得します。
サービスアカウントキーとは?
サービスアカウントキーとは、GCPが提供するAPIを利用する際に必要となる認証情報となります。
Cloud Speech-to-Text画面右上の「認証情報を作成」ボタンをクリックし、
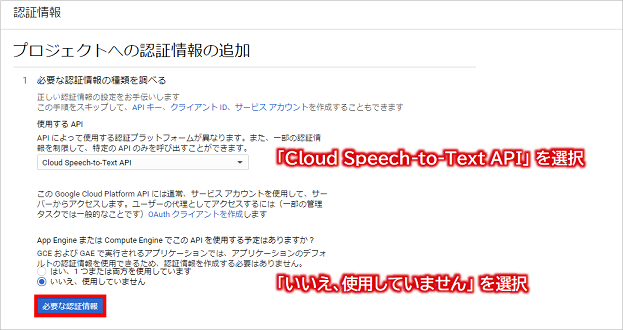
次の画面にて以下の情報を設定し、「必要な認証情報」ボタンをクリックします。
- 【使用するAPI】Cloud Speech-to-Text API
- 【App EngineまたはCompute EngineでこのAPIを使用する予定はありますか?】いいえ、使用していません
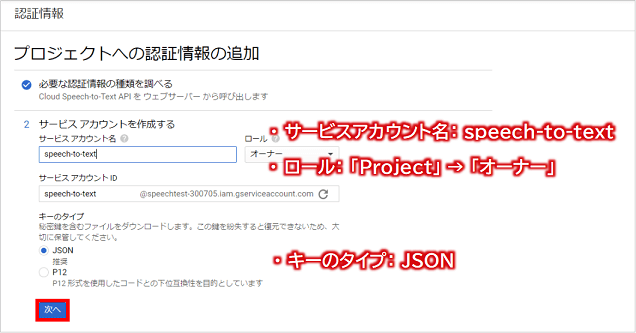
そして、次の画面にて以下の情報を設定し、「次へ」ボタンをクリックします。
- 【サービスアカウント名】speech-to-text
- 【ロール】Project → オーナー
- 【キーのタイプ】JSON
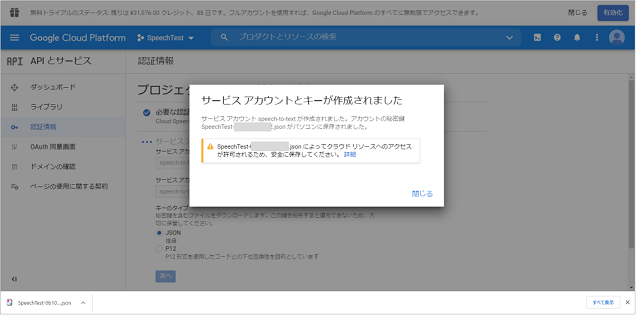
成功すると、サービスアカウントキー(JSONファイル)がダウンロードされますので、パソコンに保存しておきます。(あとで利用します。)
これでCloud Speech-to-Text APIをコールすることができるようになりました。
【STEP2】Python環境を準備する

Pythonをインストールする
まずは、次のサイトを参考にWindows用のPythonをインストールします。(※今回は、記事執筆時点で最新の「Python 3.9.1」をインストールしました。)
Google Cloud Speech用ライブラリをインストールする
次に、pipコマンドを利用してGoogle Cloud Speech用ライブラリをインストールします。
コマンドプロンプトを起動して、下記コマンドを実行します。
1 | # pip install --upgrade google-cloud-speech |
pyaudioをインストールする
次は、Pythonでのマイク制御に必要なパッケージであるpyaudioをインストールします。
ここで、pythonのバージョンが新しいとインストールに少し苦労しますので、下記サイトから(ビルド済の)バイナリを持ってくることにします。
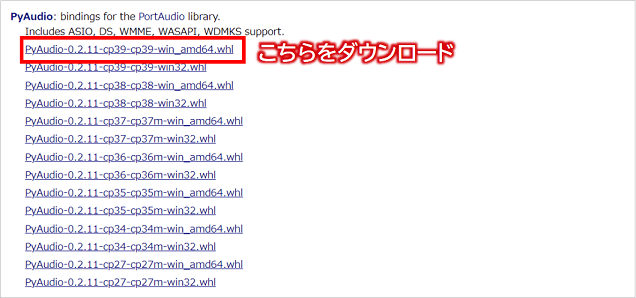
今回は、64ビット版Windows+Python3.9なので、以下のバイナリをダウンロードします。(※cp39の39はPythonのバージョンとなります。)
- PyAudio-0.2.11-cp39-cp39-win_amd64.whl
ダウンロードできましたら、コマンドプロンプトを起動し、pipコマンドによりインストールします。
1 | # pip install PyAudio-0.2.11-cp39-cp39-win_amd64.whl |
サービスアカウントキーの情報を登録する
最後は、先ほど入手したサービスアカウントキーの保存先情報をシステム環境変数に登録しておきます。
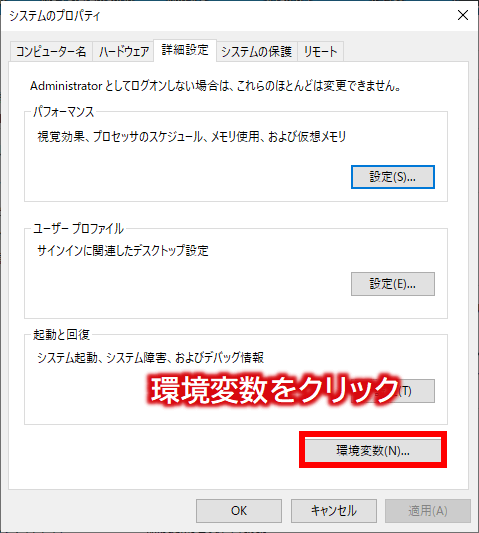
デスクトップ画面上の「PCアイコン」を右クリックして「プロパティ」を選択後、次の画面にて「システムの詳細設定」をクリックし、

システムのプロパティ画面の「環境変数」ボタンをクリックします。
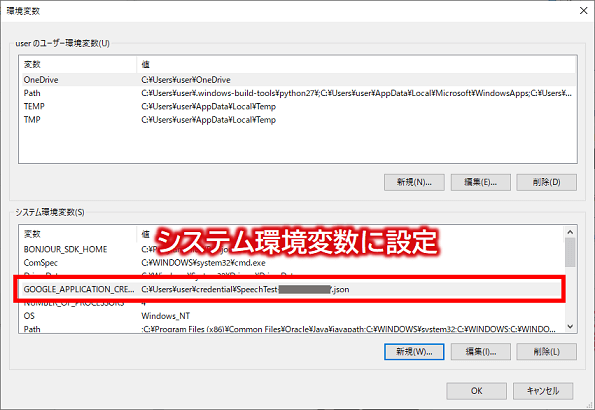
そして、次の環境変数画面にて、システム環境変数に"サービスアカウントキーのパス"を登録します。
【変数名】GOOGLE_APPLICATION_CREDENTIALS
【変数値】C:\Users\user\credential\SpeechTest-xxxxx.json (※サービスアカウントキーの保存先はお好きな場所で構いません)
以上でPython環境の準備は完了となります。
【STEP3】ZOOM会議の録音データを準備する

ZOOM会議の録音データの準備
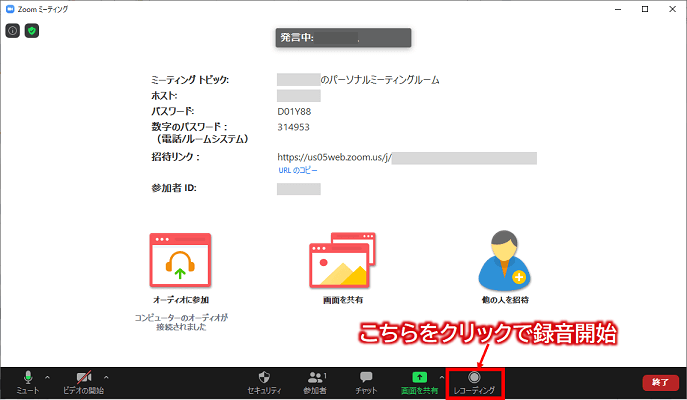
それではZOOM会議の録音データを準備してください。
ちなみに、ZOOM会議の録音は画面下の「レコーディング」で行えます。
そしてレコーディングされる録音データは「audio_only.m4a」というファイル名となります。
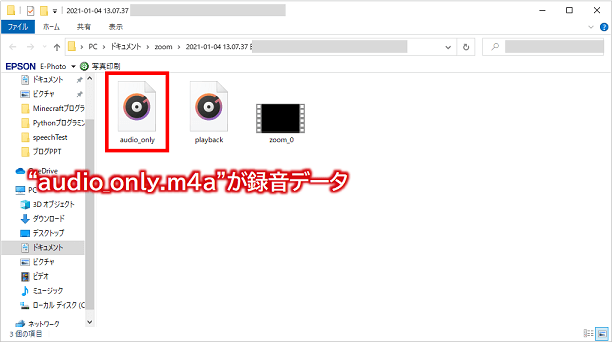
m4aとは?
m4aとは、MP3規格の進化版となるAAC(Advanced Audio Coding)規格で圧縮された音声ファイルに付く拡張子のこと。
ちなみに今回は次のようなテスト録音を行いました。(かなり短い会議ですが、、、笑)
これから開発会議を始めます。
前回の議事録を確認します。
テストです。テストです。
これで開発会議を終わります。
次回は1月30日を予定しております。
録音データの変換
次に、Speech-to-Text APIで扱いやすくするように録音データを変換しておきたいと思います。(m4aからflacへ変換します。)
変換には、無料でオンライン変換できるWebサービス(Online Audio Converter)を利用します。
アクセスできましたら、①項目にある「ファイルを開く」ボタンを押し、先ほどZOOM会議で録音した録音データ(ファイル)を指定します。
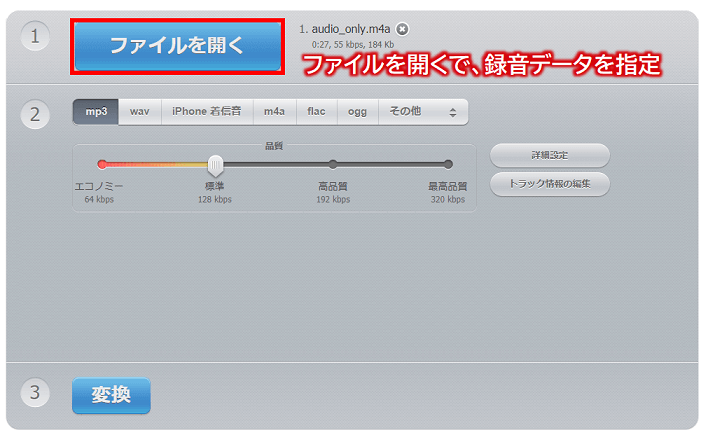
次に、②項目にて「flac」を選択後、「詳細設定」ボタンを押し、チャンネル数を「2」から「1」に変更します。
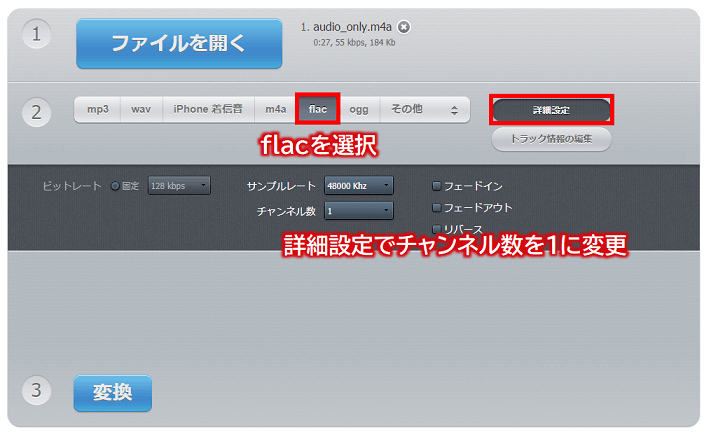
最後、③項目にて「変換」ボタンを押すと変換が始まりますので終わりましたらダウンロードリンクから録音データをダウンロードします。
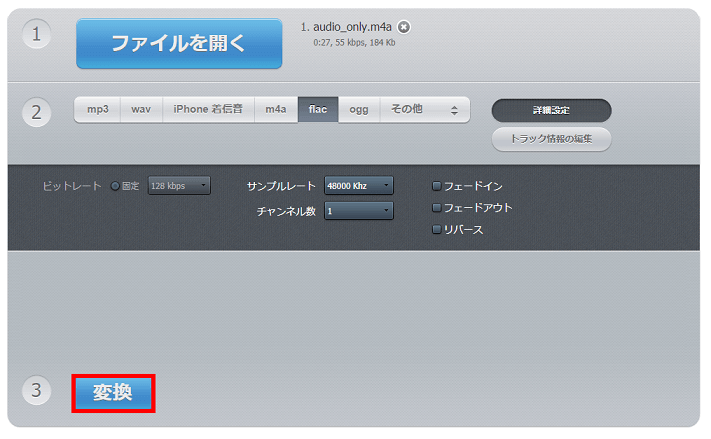
以上でテスト用の録音データの準備は完了となります。
【STEP4】Cloud Speech APIを使って議事録を作れるか確認する

Pythonでプログラムを書く
まずは、Cloud Speech APIを用いるPythonプログラムですが、次のような感じになります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | import io import os from google.cloud import speech # 議事録ファイルをオープン f = open('my_minutes.txt', 'w', encoding='UTF-8') # クライアントの生成 client = speech.SpeechClient() # 録音データを開く file_name = os.path.join(os.path.dirname(__file__), "resources", "audio_only.flac") # 録音データの読み込み with io.open(file_name, "rb") as audio_file: content = audio_file.read() audio = speech.RecognitionAudio(content=content) # 録音データの設定を記述 config = speech.RecognitionConfig( encoding=speech.RecognitionConfig.AudioEncoding.FLAC, sample_rate_hertz=48000, language_code="ja-JP", ) # 録音データをテキストに変換 response = client.recognize(config=config, audio=audio) # 議事録ファイルへ出力 for result in response.results: f.write(result.alternatives[0].transcript) # 議事録ファイルをクローズ f.close() |
このプログラムでは、『ZOOM会議システムで録音した録音データをCloud Speech-to-Text APIを使ってGoogle音声認識エンジンに渡し、返ってきた認識結果(テキスト)を議事録ファイルに出力する』、機能を実現しています。
Cloud Speech-to-Text APIのリファレンス情報は下記リンク先にて確認くださいね。
プログラム自体はとても簡単ですよね。音声認識処理をこんなに短くコーディングできるのはCloud Speech-to-Text APIのおかけですね。
Pythonプログラムを実行する
最後に作ったプログラムを実行して無事議事録が作成できるか確認してみましょう。(Pythonプログラムや録音データのフォルダ構成は次のようにしています。)
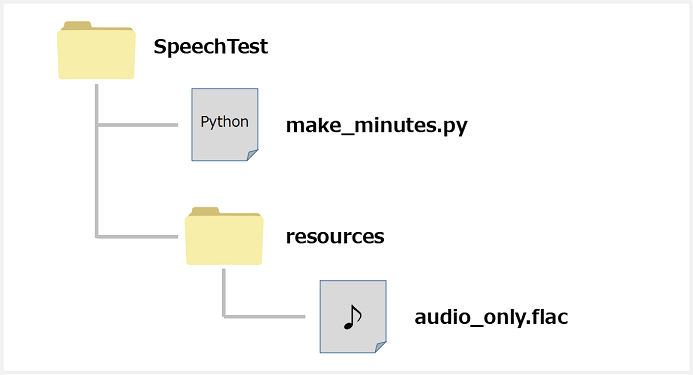
コマンドプロンプトを起動して、次のコマンドを実行します。
1 | # python make_minutes.py |
エラーなく実行できましたでしょうか?
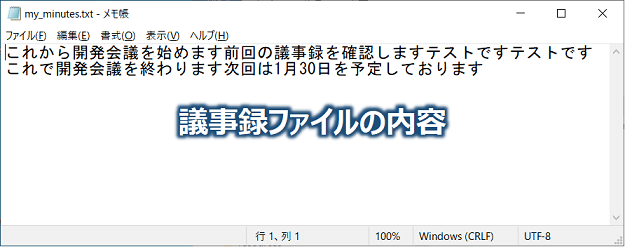
成功すると、議事録ファイル(my_minutes.txt)が作成されていると思います。
それを恐る恐る見てみると、、、無事しゃべった内容を文字列に変換してくれていますね。パチパチパチ。👏
(発言と発言の区切りがなかったりするのは今後の課題ですね。苦笑)
以上で今回の記事は終了となります。最後までご覧いただきありがとうございました。(^^)
もっと体系的にPython+AIを学びたい!って方におすすめのプログラミングスクールを紹介しております。
-
【徹底取材】PythonでAI・機械学習が学べるプログラミングスクールおすすめ6選を比較!
つづきを見る
まとめ
いかがでしたでしょうか?
今回は、ZOOM会議の録音データから議事録の自動生成をPythonでできるか確認するため、次のことにトライしました。
【今回の取り組みで試したこと】
- Cloud Speech-to-Text APIを使えるようにアカウント登録する
- Cloud Speech-to-Text APIを使えるようにPython環境を構築する
- 録音データをCloud Speech-to-Text APIに与え、音声認識により議事録が作成できるか確認する
次回また面白いユースケースを見つけて、Pythonで実現できるAIを紹介できればと考えております!
もっと体系的にPython+AIを学びたい!って方におすすめのプログラミングスクールを紹介しております。
-
【徹底取材】PythonでAI・機械学習が学べるプログラミングスクールおすすめ6選を比較!
つづきを見る