

今、「AIエンジニアになりたい!」って方が増えています。
そんな憧れの職種(?)ですが、現在私は現役AIエンジニアとしてAI関連のシステム開発(具体的にはレコメンド技術を使ったWebサービス開発)に携わっております。(まあ、こんな感じで仕事しています。(^-^))

私の紹介はここまでにして、、、今回は私の好きなアニメ「攻殻機動隊」のあるシーンをPythonで再現できるか試してみたいと思います。
そのシーンは次のような、タチコマ(ロボット)が路面店で売られている『焼き鳥』を認識する、というシーンです。

【出典】攻殻機動隊 「タチコマの家出」より
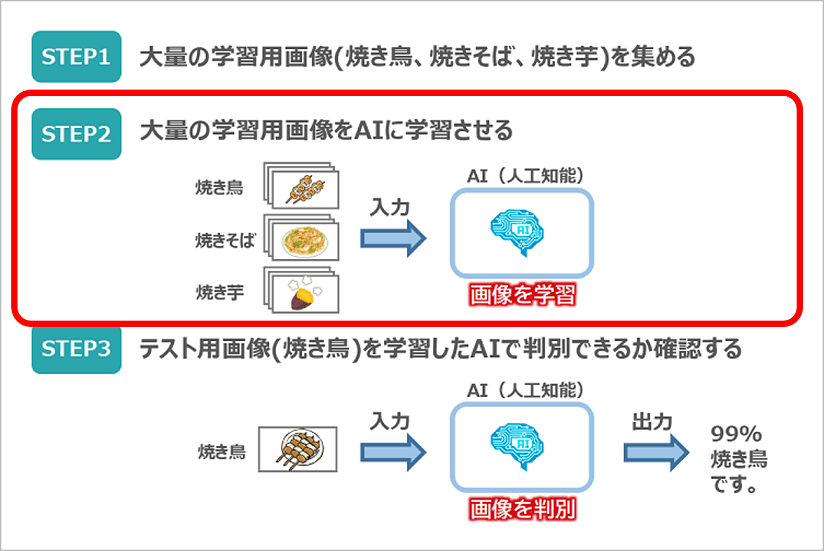
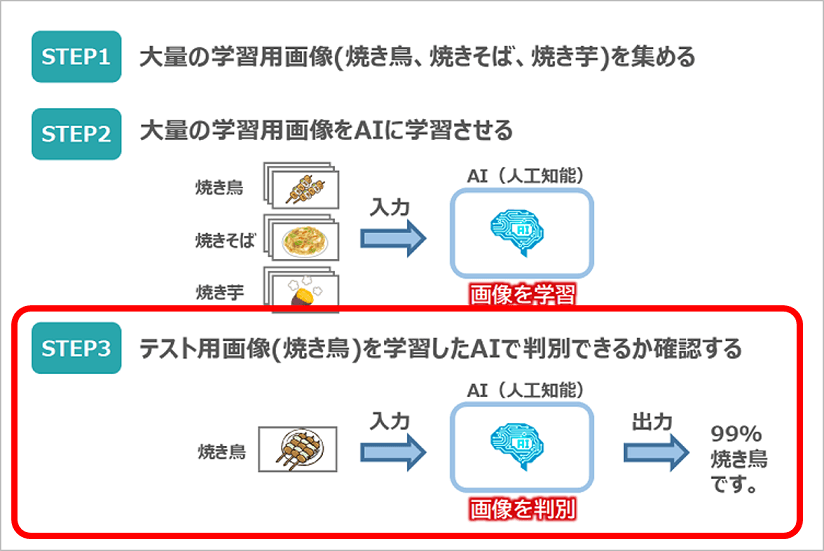
このシーンを再現するために、次の3ステップで取り組んでいきます。
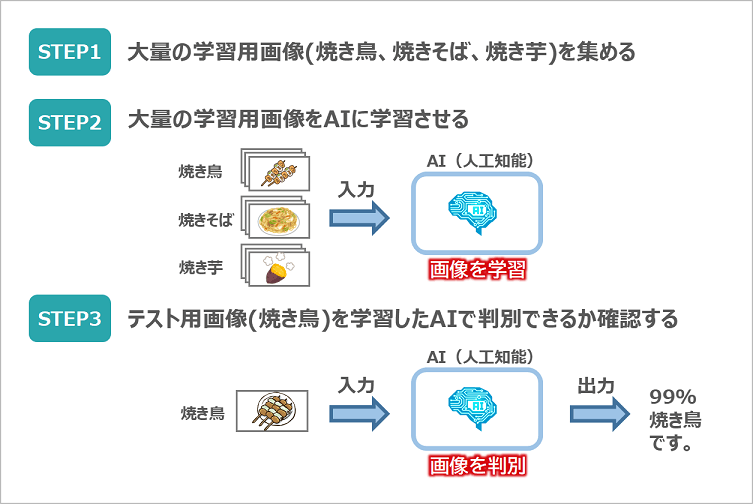
STEP1で、学習用の画像(焼き鳥、焼きそば、焼き芋)を集めるところから始めます。その際、学習には大量の画像が必要となりますので写真のコミュニティサイトであるFlickrを活用したいと思います。
次のSTEP2では、集めた大量の3種類の画像をAIに学習させます。今回はこのAIエンジンにディープラーニングを活用していきます。
最後STEP3では、学習したAIエンジンに新たな焼き鳥画像を入力し、焼き鳥と認識できるかどうかを確認します。

もっと体系的にAIを学びたい!って方におすすめのプログラミングスクールを紹介しております。
-

【徹底取材】PythonでAI・機械学習が学べるプログラミングスクールおすすめ6選を比較!
つづきを見る

【STEP1】大量の学習用画像を集める

AIの認識精度を上げるためには、質の良い画像を大量にそろえる必要があります。ただ自分で手作業で集めるには限界がありますよね。
そこで今回は、写真の共有を目的としたコミュニティサイトである「Flickr」が提供する写真検索用のAPIを利用して大量の画像を集めることにします。
今回は、焼き鳥の写真を含む3種類(①焼き鳥、②焼きそば、③焼き芋)の画像を集めていきます。
Flickr APIを使うためのキーの取得
まずは、FlickrのWebサイトにアクセスし、「Sign Up」ボタンをクリックします。
そして、氏名、メールアドレス、パスワードを入力し、「Sign Up」ボタンを押下します。(すぐに、登録したメールアドレスに確認メールが届きますので、メール本文の「Confirm my Flickr account」をクリックします。)
次にFlickr APIのページにアクセスし、画面上部にある「Create an App」リンクをクリックします。
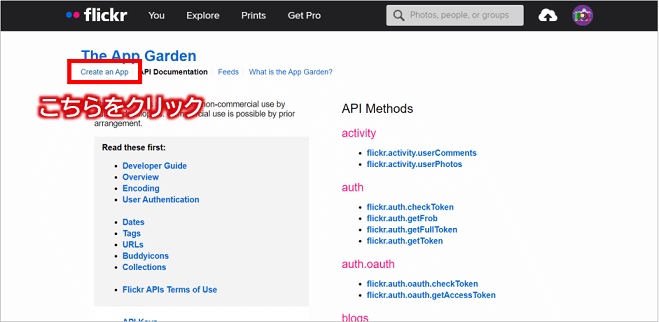
そして、「①Get your API Key」項目の「Request an API Key」リンクをクリックし、
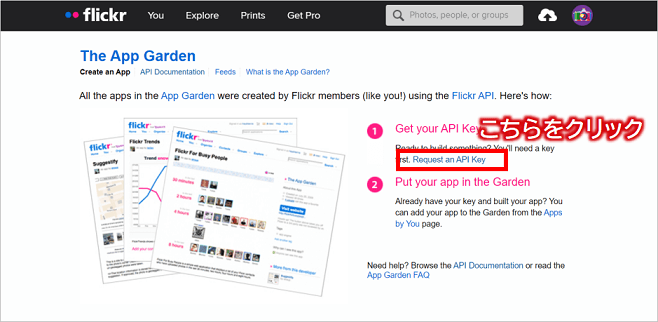
次の画面にある「APPLY FOR A NON-COMMERCIAL KEY」ボタンをクリックします。
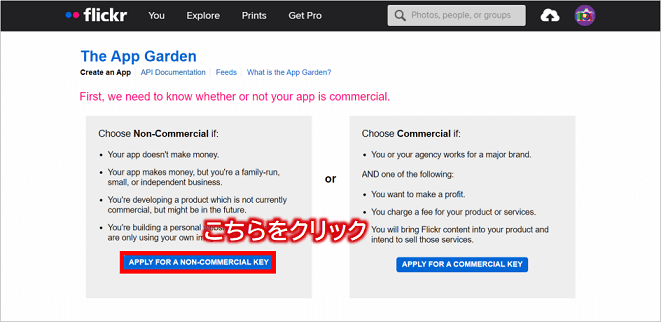
そして、次の画面にて作成するアプリの名前とそのアプリの情報を入力して、「SUBMIT」ボタンをクリックします。
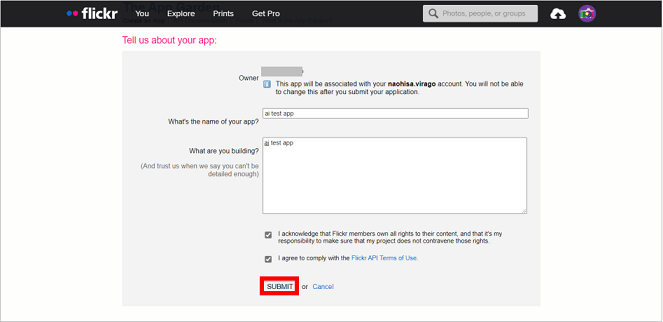
すると、「API Key」と「Secret Key」の情報が表示されますので、この2つをどこかにコピー保存しておきましょう。
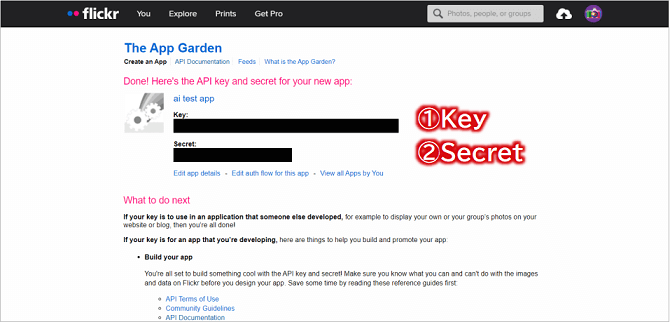
これで、Flickr APIを使う準備が整いました。
画像のダウンロード
以下のPythonプログラムは、Flickrサイトから『焼き鳥』の画像(150x150ピクセルの正方形)を300枚ダウンロードし、あなたのPCに保存するプログラムとなります。
メモ
※ソースコード中のkey変数とsecret変数には、先ほど入手したAPI KeyとSecret Keyを書いてください。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | from flickrapi import FlickrAPI from urllib.request import urlretrieve import os, time, sys # 取得したAPI Key key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" # 取得したSecrect Key secret = "xxxxxxxxxxxxxxxx" # 検索キーワード keyword = "焼き鳥" # 画像を保存するフォルダ savedir = "./image/yakitori" # 画像を保存するフォルダを作成 os.makedirs(savedir) # Flickr APIを使って検索を実行 flickr = FlickrAPI(key, secret, format='parsed-json') result = flickr.photos.search( # 検索キーワード text = keyword, # 取得する画像数 per_page = 300, # 写真を対象 media = 'photos', # 最新の画像から取得 sort = 'relevance', # 暴力的な画像を排除 safe_search = 1, # オプション(データURL、ライセンスタイプ) extras = 'url_q, license' ) photos = result['photos'] # データURLを元に1枚ずつ画像を取得しフォルダ内に保存 for i, photo in enumerate(photos['photo']): url_q = photo['url_q'] filepath = savedir + '/' + photo['id'] + '.jpg' if os.path.exists(filepath): continue urlretrieve(url_q, filepath) time.sleep(1) |
それではこのプログラムを実行してみましょう。
無事実行できましたら、image/yakitoriフォルダに、300枚の焼き鳥画像が保存できていると思います。
あと、「焼きそば」と「焼き芋」の画像も集めたいと思いますので、以下の箇所を変更して再度プログラムを実行してください。
- ソースコード中のkeywordを"焼きそば"、savedirを"./image/yakisoba"に変更
- ソースコード中のkeywordを"焼き芋"、savedirを"./image/yakiimo"に変更
不要な画像の削除
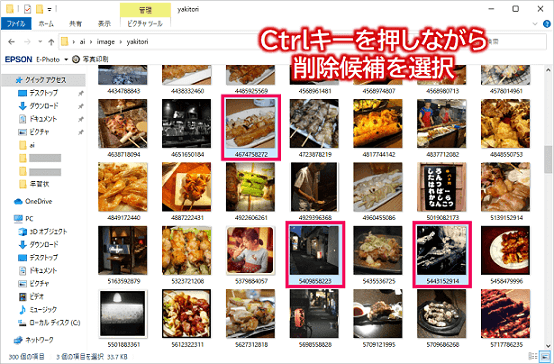
ダウンロードした画像を眺めてもらうと分かると思いますが、関係のない画像が結構含まれていたりします。このような画像があると認識精度が落ちてしまいます。
面倒な作業になりますが関係のない画像は削除して、それぞれを150枚に厳選しておきます。
メモ
Windowsの例になりますが、「Ctrl」キーを押しながら画像を選択すると複数一気に削除候補を選べますので効率よく削除できますよ。
画像をNumpy形式にまとめる
メモ
Numpyとは、Pythonで数値計算を効率的に行うためのライブラリのことです。
以下のPythonプログラムは、Flickrサイトからダウンロードした3種類の画像群を読み込んで各々の画像に分類ラベルを付与してNumpy形式でファイル保存するプログラムとなります。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | import numpy as np from PIL import Image import os, glob, random # 出力ファイル outfile = "image/food_photos.npz" # 画像数 max_photo = 150 # 画像の縦横サイズ(ピクセル) photo_size = 150 x = [] y = [] # ディレクトリ以下の画像を読み込んでNumpy配列に追加する関数 # 第一引数:画像のディレクトリパス、第二引数:分類ラベル def read_files(path, label): files = glob.glob(path + "/*jpg") random.shuffle(files) num = 0 for f in files: if num >= max_photo: break num += 1 img = Image.open(f) img = img.convert("RGB") img = img.resize((photo_size, photo_size)) img = np.asarray(img) x.append(img) y.append(label) # 焼き鳥の画像には分類ラベル0、焼きそばは分類ラベル1、焼き芋は分類ラベル2を付与 read_files("./image/yakitori", 0) read_files("./image/yakisoba", 1) read_files("./image/yakiimo", 2) # Numpy形式でファイルに保存 np.savez(outfile, x=x, y=y) |
【STEP2】大量の学習用画像をAIに学習させる

集めた大量の学習用画像をAIに学習させていきますが、今回はAIエンジンとしてディープラーニングの画像認識に関する代表的な手法である「CNN:畳み込みニューラルネットワーク」を用いたいと思います。
AIエンジンを作成する
それでは、さっそくAIエンジンを作っていきましょう。
まずは、CNNモデルを定義して返却するコードを作成しておきます。
〇〇層とか、最適化関数とか、聞き慣れない用語がいっぱい出てくると思いますが、とりあえず細かい説明は別の機会に行いたいと思いますので、まずはこんな書き方するのね、ぐらいで考えてもらえればと思います。(笑)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten, Activation from keras.layers import Conv2D, MaxPool2D from keras.optimizers import Adam # CNNモデルを定義して返却する関数 def get_model(in_shape, num_classes): # 特徴量抽出 model = Sequential() model.add(Conv2D(32,3,input_shape=in_shape)) # 畳み込みフィルタ層 model.add(Activation('relu')) # 最適化関数 model.add(Conv2D(32,3)) model.add(Activation('relu')) model.add(MaxPool2D(pool_size=(2,2))) # プーリング層 model.add(Conv2D(64,3)) model.add(Activation('relu')) model.add(MaxPool2D(pool_size=(2,2))) # 特徴量に基づいた分類 model.add(Flatten()) # 全結合層入力のためのデータの一次元化 model.add(Dense(1024)) # 全結合層 model.add(Activation('relu')) # 最適化関数 model.add(Dropout(0.5)) # ドロップアウト層 model.add(Dense(num_classes, activation='softmax')) # 出力層 # モデルのコンパイル adam = Adam(lr=1e-4) model.compile(optimizer=adam, loss='categorical_crossentropy', metrics=["accuracy"]) return model |
AIエンジンに画像を学習させる
次に、定義したCNNモデルに画像を学習させてみましょう。
次のコードでは、Numpy形式でファイル保存した画像データを読み出して、xに画像データを、yにその画像の分類ラベル(焼き鳥なら1、焼きそばなら2、焼き芋なら3)を入れます。
そして、それらの画像データを先ほど定義したCNNモデルに与えて画像を学習をさせ、学習したモデルをファイルに保存する、といった流れになります。(※ここでモデルをファイルに保存する理由は、学習にはかなりの時間を要するので、一度学習したモデルをすぐに再利用するためです。)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | import cnn_model import keras import numpy as np from sklearn.model_selection import train_test_split im_rows = 150 # 画像の縦サイズ(ピクセル) im_cols = 150 # 画像の横サイズ(ピクセル) im_color = 3 # 画像の色空間 in_shape = (im_rows, im_cols, im_color) num_classes = 3 # 分類数 # 写真データを読み込み food_photos = np.load('image/food_photos.npz') x = food_photos['x'] y = food_photos['y'] # 読み込んだデータを三次元配列に変換 x = x.reshape(-1, im_rows, im_cols, im_color) x = x.astype('float32') / 255 y = keras.utils.to_categorical(y.astype('int32'), num_classes) # 学習用とテスト用に分ける x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8) # CNNモデルを取得 model = cnn_model.get_model(in_shape, num_classes) # モデルの学習 hist = model.fit(x_train, y_train, batch_size=32, epochs=50, verbose=1, validation_data=(x_test, y_test)) #モデルを評価 score = model.evaluate(x_test, y_test, verbose=1) print("正解率=", score[1], "loss=", score[0]) # 学習したモデルを保存 model.save_weights('./image/food_photos_model.hdf5') |
【STEP3】テスト用画像を学習したAIで判別できるか確認する

それでは、学習したAIエンジンに自分で撮影した「焼き鳥」の画像を与えて、無事に焼き鳥と認識できるかやってみたいと思います。(ファイル名は、"test-yakitori.jpg"としております。)
次のプログラムでは、先ほど保存したAIエンジン読み込み、そのAIエンジンに焼き鳥の画像を与えて認識率(%)を結果として出力するプログラムとなります。
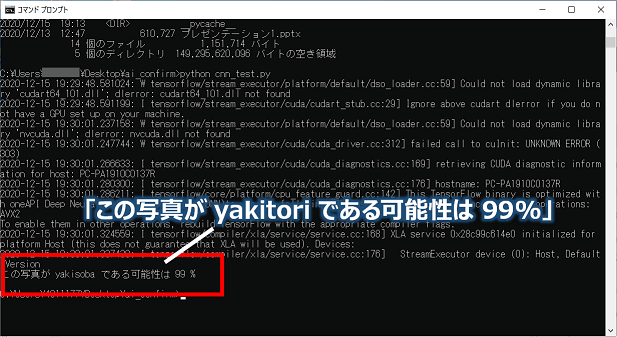
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | import cnn_model import numpy as np from PIL import Image target_image = "test-yakitori.jpg" # テスト用画像 im_rows = 150 # 画像の縦ピクセルサイズ im_cols = 150 # 画像の横ピクセルサイズ im_color = 3 # 画像の色空間 in_shape = (im_rows, im_cols, im_color) num_classes = 3 # 分類数 LABELS = ["yakitori", "yakisoba", "yakiimo"] # 分類ラベル数 # CNNモデルを取得 model = cnn_model.get_model(in_shape, num_classes) # 保存したモデルを読み込む model.load_weights('./image/food_photos_model.hdf5') # 画像を読み込む img = Image.open(target_image) img = img.convert("RGB") # 色空間をRGBに img = img.resize((im_cols, im_rows)) # サイズ変更 # データに変換 x = np.asarray(img) x = x.reshape(-1, im_rows, im_cols, im_color) x = x / 255 # 予測 pre = model.predict([x])[0] idx = pre.argmax() per = int(pre[idx] * 100) print("この写真が", LABELS[idx], "である可能性は", per, "%") |
最後このプログラムを実行してみると、、、パーセントは「99%」となりました。パチパチパチ。
以上で今回の記事は終了となります。最後までご覧いただきありがとうございました。(^^)
もっと体系的にAIを学びたい!って方におすすめのプログラミングスクールを紹介しております。
-
【徹底取材】PythonでAI・機械学習が学べるプログラミングスクールおすすめ6選を比較!
つづきを見る
まとめ
いかがでしたでしょうか?
今回は、アニメ攻殻機動隊のワンシーンである「タチコマが路面店で売られている『焼き鳥』を認識するシーン」をPythonで再現できるか確認するため、次のことにトライしました。
【今回の取り組みで試したこと】
- Flickr APIを使って大量の画像を集める
- AIエンジンを作成する
- 集めた大量の画像をAIエンジンに与え、学習させる
- 学習させたAIエンジンにテスト画像を与え、認識できるか確認する
次回また面白いユースケースを見つけて、Pythonで実現できるAIを紹介できればと考えております!
もっと体系的にAIを学びたい!って方におすすめのプログラミングスクールを紹介しております。
-
【徹底取材】PythonでAI・機械学習が学べるプログラミングスクールおすすめ6選を比較!
つづきを見る